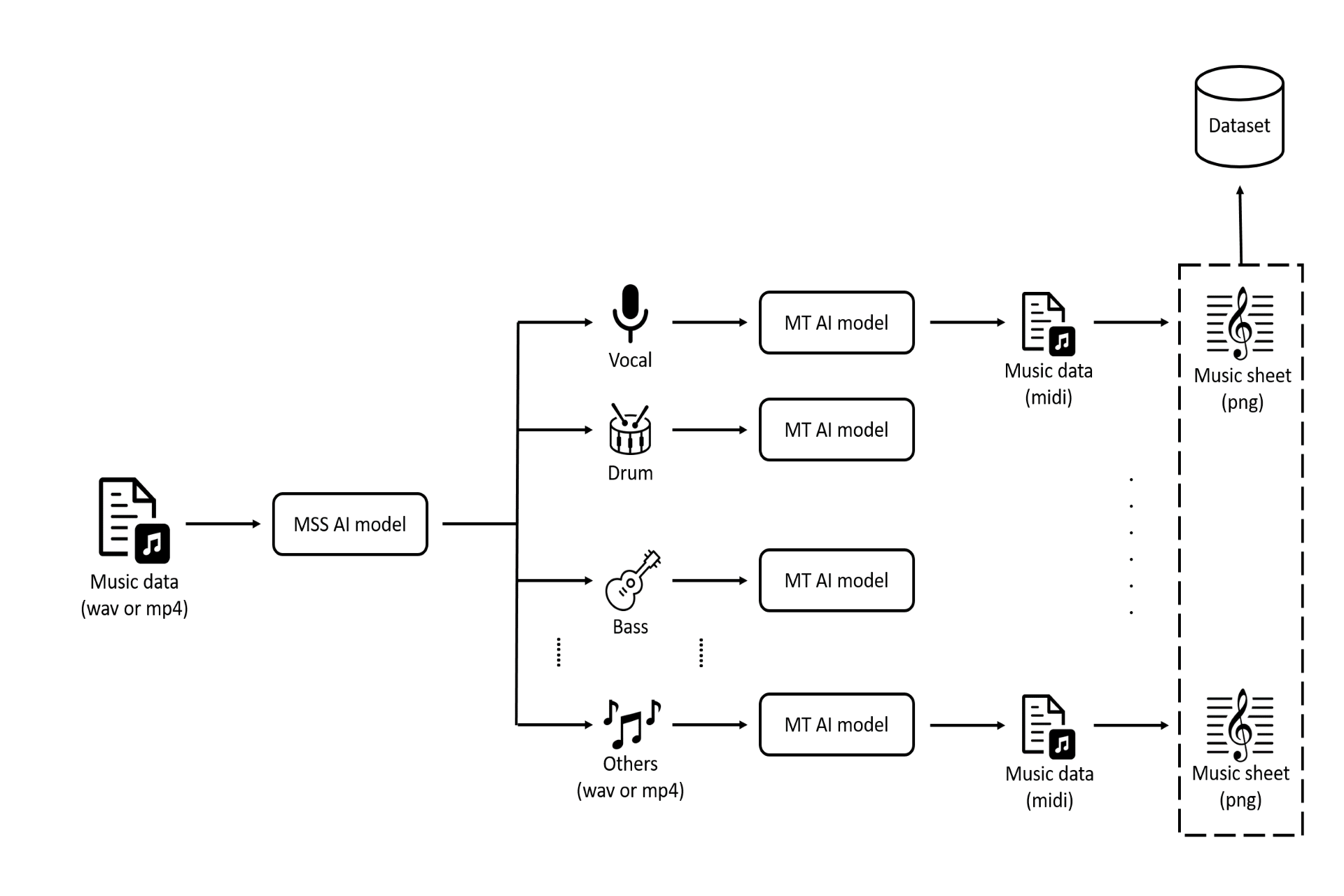
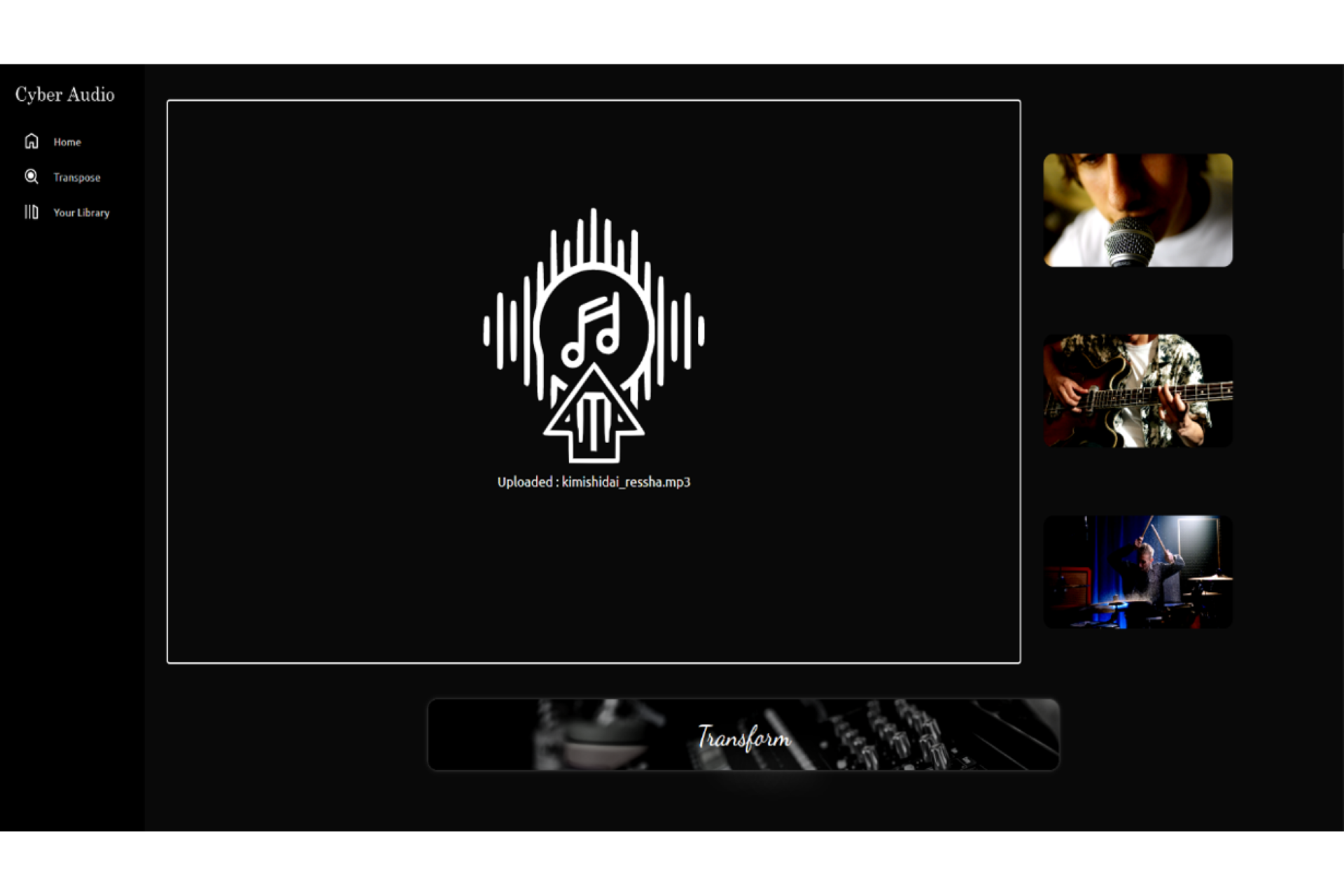
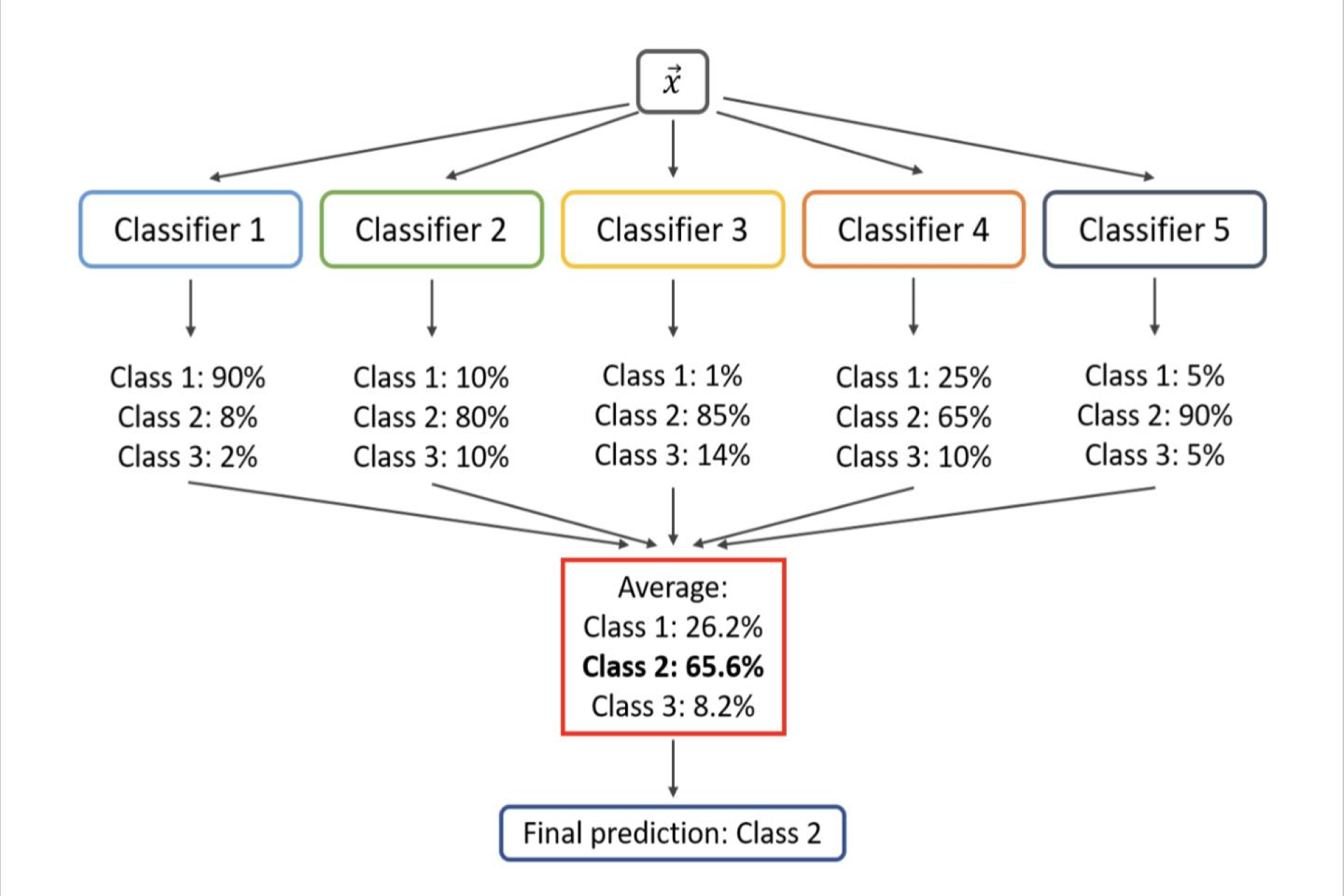
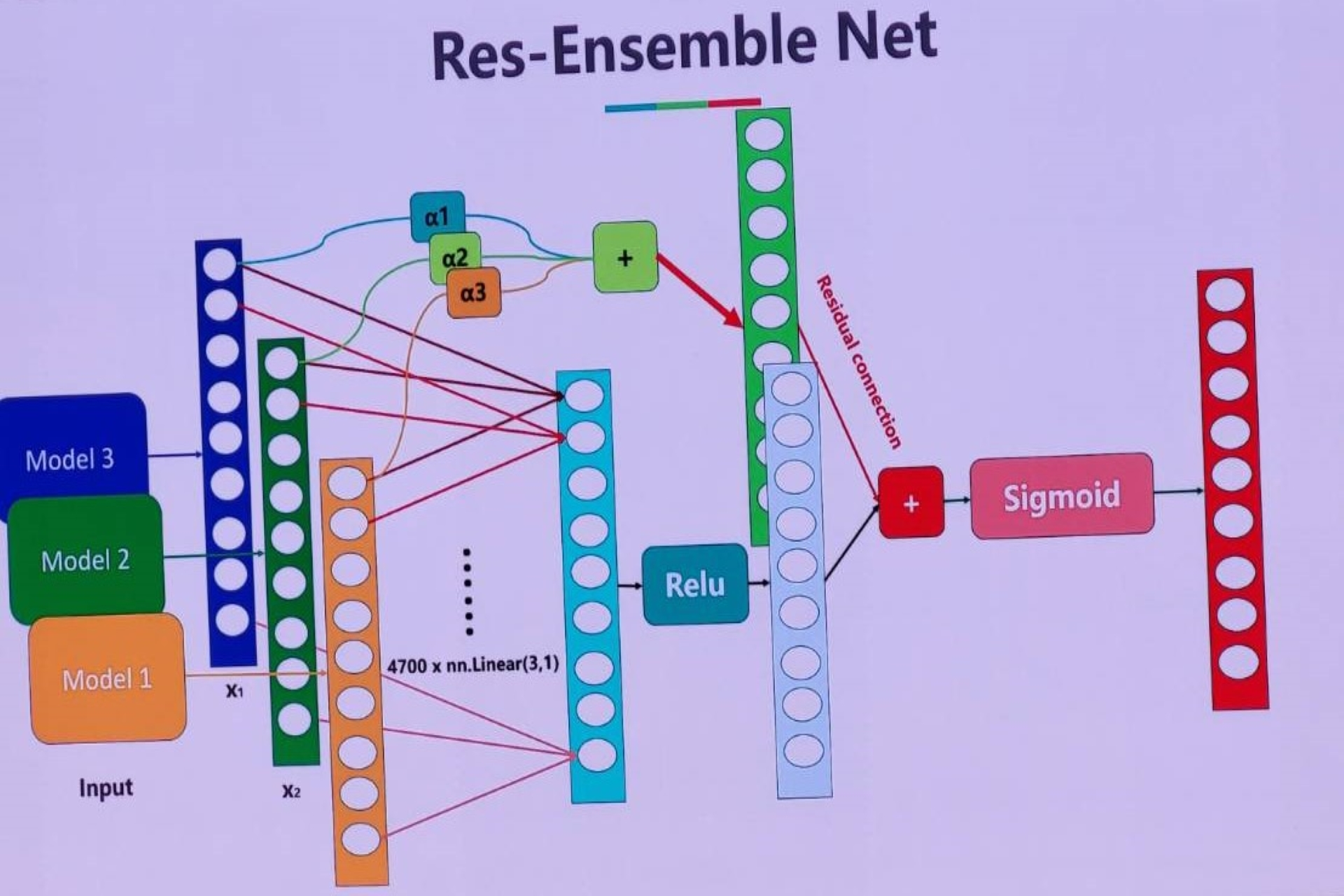
AI R&D Engineer 2022 - now
As an R&D Engineer at ASUS DIT, I develop and implement computer vision algorithms using AI, while collaborating with both front-end and back-end teams to create innovative solutions for clients. My technical skills, communication abilities, and project management expertise have enabled me to successfully deliver projects and provide effective solutions to clients.